分布式一致性协议 - ZAB
条评论ZAB 背景
学习ZAB,非常有必要聊聊它诞生的背景。因为在paxos的光芒下,还有必要折腾这样类似的算法吗?这个问题是我们初步了解ZAB关键。
看到这里,我断定大家都使用过zookeeper,并且知道zookeeper的核心就是ZAB协议。如果没有的话,需要先学习下zookeeper。毕竟基础不牢,地动山摇。
这里多提一句,ZAB的作者说ZAB不是paxos,但是后面我们又把ZAB归纳为paxos。这里我认为啊,这两个说法都对,只是他们描述的时间不一致。在ZAB诞生的时候,它解决了paxos不能保证顺序执行的问题,从某些角度来说ZAB是要paxos优秀的,说它不是paxos也没问题。但是后来随来越来越多分布式算法诞生,例如raft,因为他们都类似paxos执行逻辑,所以将这类算法归纳为paxos的变种。
为何不使用paxos来实现zookeeper
回过头来,ZAB诞生的原因,我们先考虑zookeeper能不能直接使用paxos作为分布式一致性算法?答案肯定是否定的,我们举个例子,假设有个客户端需要分别创建目录:/foo, /foo/ofcoder。
在前文我们学习过了paxos,知道paxos能集群就某个值达成共识,但是却不关心达成共识的值是什么。如果zookeeper直接使用paxos,就会出现在没有创建/foo的时候,创建/foo/ofcoder。显然这就报错了,因为ofcoder的上级目录不存在。为了描述这个问题,我们描述下过程。
假如有同一个业务请求,因为入参不一样,导致最后要达成共识的值也不一样。例如proposerA,收到请求先后创建/foo, /foo/ofcoder两个节点。proposerB收到请求先后创建/method,/method/far节点。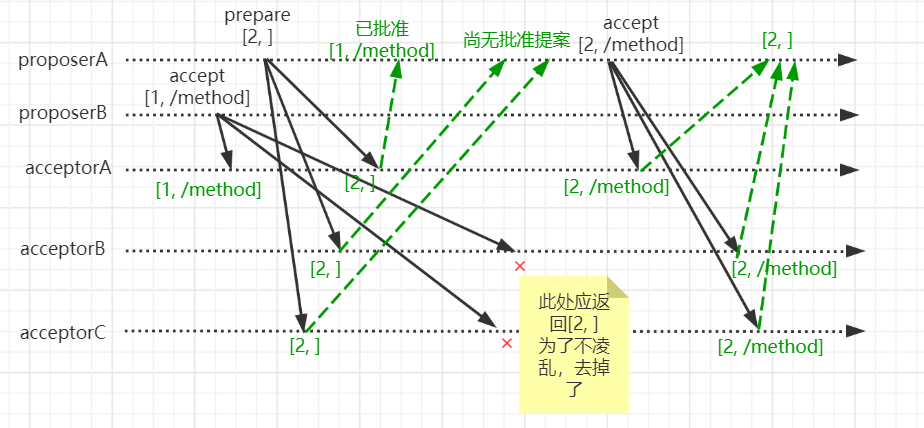
- proposerB先发起paxos的prepare阶段,并获得大多数选票,开始accept阶段。
- 在proposerB的accept阶段,只有acceptA接收了提案[1, /method],其他节点都通过了proposerA的prepare请求。
- 根据规定,proposeA的accept的提案应该为[2, /method],并通过该提案。
- 此时proposerB重新开始paxos的两个阶段,得到达成共识的提案是[2, /method]。
- proposerA开始第二个值的paxos过程,即/foo/ofcoder。
到此为止,可以看到当proposerA开始创建/foo/ofcoder时,则会发现/foo没有创建而导致失败。因为在第一轮paxos在集群中达成共识的值/method。
通过上面的过程,我们更加论证了,paxos只适合在集群中使某个值达成共识,而不关心达成共识的值是什么。而在zookeeper中,这显然是不能满足业务需求的。
ZAB术语科普
ZAB并不像paxos,是一种通用的分布式一致性算法,ZAB是一种专门为zookeeper设计的崩溃可恢复的原子广播协议。相比于paxos,ZAB主要解决了事务操作的顺序性,在ZAB协议中,如果一个事务操作被处理了,那么所有其依赖的事务操作都应该被提前处理了。
在学习ZAB之前,我们需要先整理几个术语、因为在ZAB的论文中,术语相对比较多,并且概念冗余。例如:
- 提案(proposal):进行协商的基本单元,在一些文档中,也有称之为操作(operation)、指令(command)。
- 事务(transaction):也是指提案,常出现在代码中,并非指具有ACID特性的一组操作。
- 已提出的Proposal:指广播的第一阶段所提出的Proposal,未提交到状态机的Proposal。
- 已提交的Proposal:指广播的第二阶段已提交到状态机的Proposal。
为了帮助我们理解,ZAB定义了三个角色、四种节点状态、四种ZAB运行状态、以及两种运行模式。大家别看到我罗列了这么多,就打退堂鼓。从多个角度来归纳,只是为了更好的给大家呈现ZAB内部原理。
三个角色
领导者(leader)
leader是整个ZAB协议的核心,其工作内容在于:接收并处理所有事务请求,也就是写请求。将每个事务请求,封装成提案(proposal)广播给每个跟随者(follower),根据跟随者(follower)返回请求,控制是否需要提交该提案。跟随者(follower)follower的工作,可以分为三部分
- 接收leader提出的提案(proposal),参与对提案(proposal)的投票
- 接收并处理非事务请求,也就是读请求。如果follower收到客户端的事务请求,则会将其转发给leader进行处理。
- 参与leader选举投票
- 观察者(observer)
跟paxos中学习者类似,增加observer,可以在不影响集群写性能的情况下,提升读性能。
四种节点状态
这是一个容易忽视的点,ZAB虽然规定了三种角色,但是他是通过定义四种状态来描述当前节点所处的角色的。包含以下状态:
- LOOKING,竞选状态,当前集群不存在Leader。该状态下会发起领导者选举。
- FOLLOWING,随从状态,同步Leader状态,参与投票。
- OBSERVING,观察状态,同步Leader状态,不参与投票。
- LEADING,领导者状态,对应Leader角色。
这里与角色对应多出来一个状态,是因为ZAB是支持自动Leader选举的,LOOKING是属于选举中的一个过渡状态。
四种ZAB运行状态
这里是指ZAB集群的运行状态,因为ZAB除了正常向外部提供服务,还得有故障恢复功能。从整个集群的状态,我们可以了解ZAB的运行过程。
- ELECTION,选举状态,表明节点正在进行Leader选举
- DISCOVERY,成员发现状态,在选举出新Leader后集群所处的状态,用于节点协商沟通Leader的合法性
- SYNCHRONIZATION,数据同步状态,在确认新Leader后,以Leader的数据为基础,修复各个节点的数据一致性
- BROADCARST,广播状态,集群处于正常运行状态,可向外提供服务
两种运行模式
从上述ZAB运行状态中,可以归纳为两种运行模式,即消息广播模式、崩溃恢复模式。
- 崩溃恢复模式:
在整个服务框架启动过程中、或者Leader服务器出现网络中断、崩溃退出等异常情况时,ZAB协议就会进入崩溃恢复模式并选举新的Leader服务器。当新的Leader服务器在集群中有过半的Follower与其完成成数据同步后,ZAB就会退出崩溃恢复模式。 - 消息广播模式:
当集群中已有过半的Follower与Leader完成数据同步,那么整个集群就会进入消息广播模式。此时整个集群才可以对外提供服务,即数据的查询、修改。
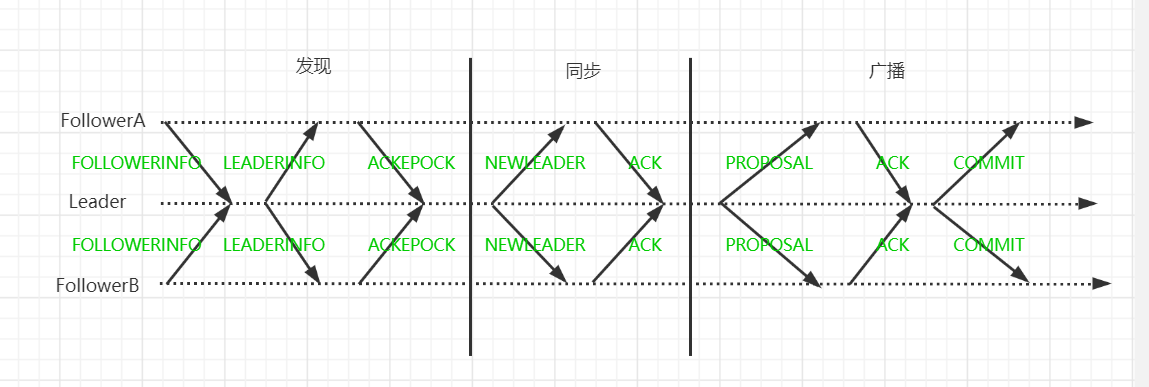
值得注意是,当一台新的ZAB节点加入集群时,该节点会先进入崩溃恢复模式,找到Leader,并与其进行数据同步,然后一起参与到消息广播流程中。所以崩溃恢复模式还分为两个阶段:发现、同步。具体后文会详细讲解。
后文讲解思路也是从这两种模式入手,在崩溃恢复模式中,再细分为三个阶段,也就是四种运行状态的前三种(ELECTION、DISCOVERY、SYNCHRONIZATION)。
zxid
这里把zxid单独拎出来描述,zxid在ZAB占据很重要的位置。Leader在收到事务请求,将其封装成Proposal时,会为每个Proposal生成对应的zxid。
在消息广播模式中zxid标志者事务请求的先后顺序,在崩溃恢复模式中zxid是Leader的选举的判断依据,以及在Leader选举后,数据同步中zxid能方便的帮助ZAB抛弃上一个Leader没完成的Proposal。所以在学习下面的内容时,要及时参考zxid的设计逻辑。
zxid它是一个64位,其中低32位可以看成一个简单的计数器,而高32位则代表了Leader周期的epoch编号。后文中使用<epoch, counter>标示一个zxid,例如<1, 101>。
- epoch,则标示者当前集群所处的周期(年代),或者说当前Leader的周期(年代)。在每一次Leader变更后,新Leader产生的epoch则会在上一任Leader的epoch上进行加1,作为自己的epoch。
- 计数器,则是针对客户端每一个事务请求,Leader在产生新的Proposal事务时,都会对该计数器加1。而Leader变更后,该计数器则会重置为0。
这样做的好处:
- 计数器,可以定义Proposal的先后顺序,保证发送提交事务消息广播顺序。
- epoch+计数器,能有效的避免zxid的冲突,不会出现Leader使用了相同编号的zxid提出了不一样的Proposal。
- 能随时获取到最新的Leader周期(epoch),当Leader收到在网络故障后,收到比他大的epoch的Proposal,则证明集群中已有其他Leader,自己则变更为Follower。
- 新Leader产生的zxid一定比上一任Leader产生zxid大。当上一任Leader宕机恢复后(以Follower角色)加入集群,如果有尚未提交的事务,则可以对比zxid进行抛弃(回退)那一些Proposal,直到回退到一个确实已经被集群中过半机器Commit的最新Proposal。
第3, 4点如果现在看不明白,在讲述崩溃恢复模式时,我会回过头来再讲讲的。
消息广播模式
总的来说,消息广播模式是一个类似于二阶段提交(2PC)过程,针对客户端事务请求,Leader将其生成对应的Proposal,并发给所有的Follower,收集各自的选票后,最后进行事务提交。与2PC不同的是,ZAB移除了第二阶段的中断逻辑。所有的Follower要么接收该Proposal,要么抛弃Leader服务器。这意味着Leader收到过半的Ack响应后就可以提交该事务了,而不需要等待所有的Follower都返回Ack。
由于ZAB为了严格保证Proposal的因果关系,即事务请求的顺序性,ZAB为每个Proposal生成对应的zxid,并严格按照zxid的顺序,进行消息的广播。具体的,Leader会为了Follower分配一个单独的队列,将消息广播前,先将Proposal按照zxid顺序依次放入这些队列中,并根据FIFO策略进行消息发送。
Follower在收到事务Proposal之后,都会将其以事务日志的形式写入本地磁盘中,并在写入成功后,返回给Leader一个Ack响应。当Leader服务器收到过半的Follower的Ack响应后,就会广播Commit消息给所有Follower通知其进行事务提交,同时Leader自身也会完成事务的提交。至此整个消息广播模式完成。
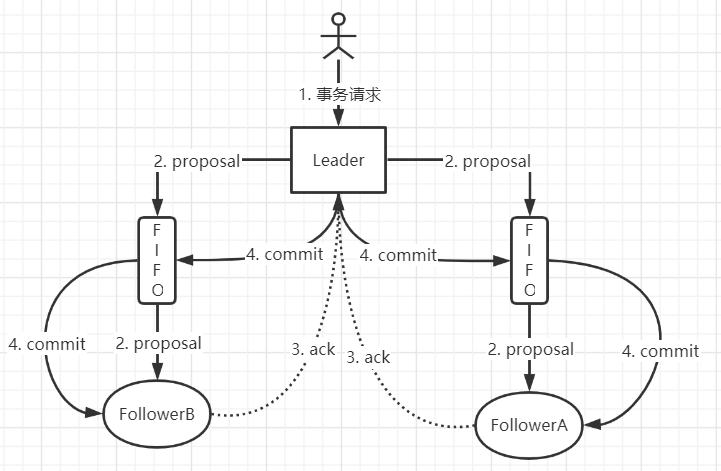
- 客户端发起事务请求,由Leader进行处理
- Leader将该请求转换为事务Proposal,同时为Proposal分配一个全局的ID,即zxid
- Leader为每个Follower维护一个FIFO队列,将上一步生成的Proposal放入队列中,进行广播
- Follower收到Proposal后,会首先将其以事务日志的方式写入本地磁盘中,写入成功后向Leader反馈一个响应消息
- Leader收到过半的Ack响应后,自己完成对该Proposal的提交后,向每个Follower的队列中,写入Commit消息进行广播
- Follower接收到Commit消息后,会将上一条事务提交
如何保证事务执行的顺序
此时,我们得回到zxid的构成那部分,ZAB就是通过zxid中计数器,来保证提交顺序的,具体如下:
在Leader收到客户端set X、set Y两个请求后,会将其封装成两个Proposal(<1, 101>: X, <1, 102>: Y)进行广播所有的Follower。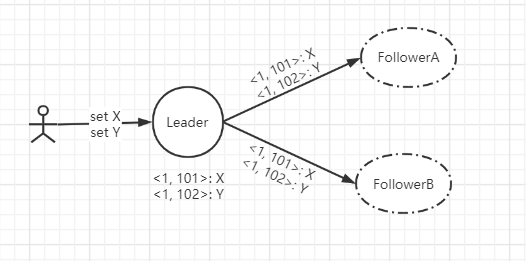
当Leader收到过半的Ack响应后,则会进行Commit消息的广播。这里需要注意,Leader提交提案是有顺序性的,按照zxid的大小,按顺序提交提案,如果前一个提案未提交,此时是不会提交后一个提案的。因此X一定在Y之前提交。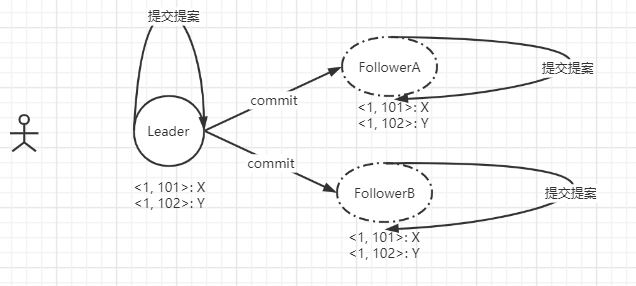
最后,Leader返回执行成功响应给客户端。完成本次消息广播。
崩溃恢复模式
通过上面的了解,我们知道了ZAB其实是一个强领导者模型的协议。消息广播模式,只能在ZAB正常运行中向外部提供服务。这也要求ZAB设计者不得不考虑,当Leader宕机或者失去过半的Follower节点后,如何恢复整个集群。
为了更好理解崩溃恢复模式原理,通常会把他分为两个阶段或者三个阶段,即(Leader选举、Leader发现)、数据同步。
基本约定
在选举新的Leader后,向外部提供服务之前,ZAB还需要保证数据正确性,即上一个Leader崩溃之时,正在处理的事务请求,可能会出现两个数据不一致的隐患。针对这样情况,ZAB保证一下特性:
- ZAB需要确保那些已经在Leader上提交的事务最终被所有服务器都提交
即:ProposalA在Leader上被提出后,收到过半的Follower的Ack响应,但是在将Commit请求广播给所有Follower机器之前,Leader宕机了。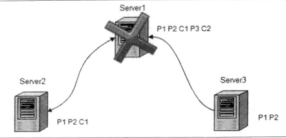
在该图中,Leader先后广播了P1, P2, C1, P3, C2。其中Leader在广播C2(P2的Commit请求)之前宕机,ZAB会在崩溃恢复模式中,让所有的服务器都提交C2。 - ZAB需要确保丢弃那些仅仅只在Leader上被提出的事务
即:该约定是指,ZAB会抛弃那些只在Leader上被提出的事务,还没有任何Follower收到该请求。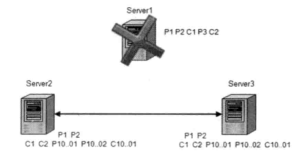
在该场景中,Leader提出P3后宕机,还没有任何Follower收到该请求,则崩溃恢复模式中,整个集群会丢弃P3的事务。
Leader选举(ELECTION)
Leader的选举,关乎着整个集群的故障容错和集群可用性,是ZAB非常核心的设计之一。而Leader选举说白了,就是对比集群中各节点的信息,选举出最合适的节点当做Leader。而最合适的节点标准是什么,则是理解Leader选举(FastLeaderElection方式)的关键。
ZAB采用的各节点广播自己所提议的Leader,收到其他节点提议的Leader后,与自己所提议的Leader进行PK,根据PK的规则重新选择提议的Leader,直到有过半的节点都提议某一节点,即结束Leader选举。
Leader选举PK的规则包含以下几个方面:
- 任期编号(epoch),优先判断epoch,epoch大的节点当选Leader
- 事务标示符(zxid),epoch相同,则比较zxid,zxid大的当选Leader
- 节点ID,epoch、zxid都一致,则比较节点ID(在myid文件中指定的值)
因为选举规则包含上述三个方面,则每个节点在广播自己所提议的Leader时,选票中都会包含上面三个值。后文使用<proposeLeader, epoch, zxid, node>,来表示一张选票,表明自己所有提议的Leader。
- proposeLeader,表示自己所提议的Leader的节点ID
- epoch,表示所提议的Leader节点所处的任期编号
- zxid,表示所提议的Leader节点拥有的Proposal最大的事务编号
- node,表示本次提议的节点
这里需要注意的是,这里的zxid是指ZAB在消息广播模式第一阶段的收到Proposal最大的zxid,即:节点收到被提出的Proposal最大的zxid,而不是已提交的Proposal最大的zxid。
这里需要单独拎出来强调,有的伙计,在看zookeeper源码时,会看到Leader选举时,使用的是dataTree.lastProcessedZxid。而dataTree.lastProcessedZxid表示的是已提交的Proposal最大的zxid。这里没错,在正常运行时dataTree.lastProcessedZxid确实表示的是已提交的Proposal最大的zxid。但是当跟随者检测到异常,退出FOLLOWING状态时,在follower.shutdown()中,会使用lastProcessedZxid表示节点上收到已提出的Proposal的zxid。而后续的Leader选举使用的lastProcessedZxid,即为节点收到被提出的Proposal最大的zxid。
算法陈述
集群中存在三个节点A, B, C,各自节点ID依次为1, 2, 3。其中A为Leader,已提交两个Proposal(<1, 101>,<1, 102>),B、C为Follower,B已提交两个Proposal(<1, 101>,<1, 102>),C只提交了<1, 101>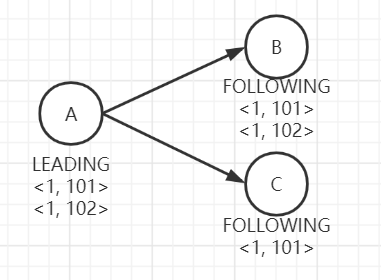
当A节点宕机后,跟随者检测Leader异常,则退出FOLLOWING状态,变更为LOOKING,发起Leader选举。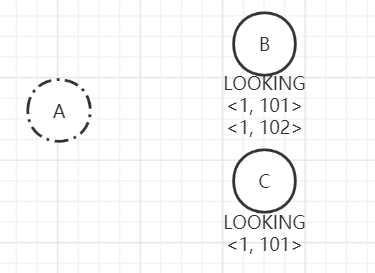
当Follower开始第一轮提议Leader时,都会推荐自己为Leader,并向所有节点广播自己的提议,即B的选票为<2, 1, 102, B>,C的选票为<3, 1, 101, C>。各自将选票发给其他节点,B的选票发送给B、C,C的选票也发送给B、C。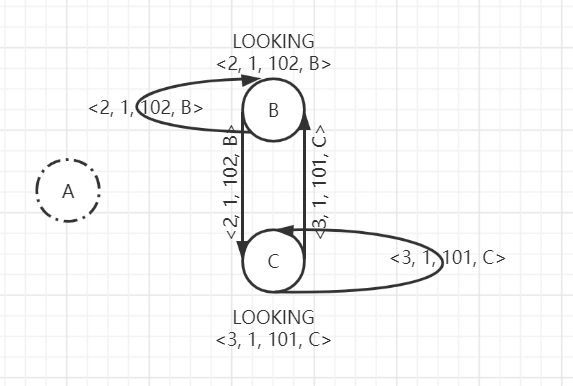
B, C收到对方的选票后,根据上面描述的规则进行PK,依次比较epoch、zxid、节点ID。B、C首先会收到来自自己的提议的选票,因为收到选票与自己提议的选票相同,只需要接受和保存该选票。
- 当B收到来自C的选票<3, 1, 101, C>,由于epoch相同,B的zxid大于C的zxid,则B的选票获胜,不需要变更选票信息,保存即可。
- C收到来自B的选票<2, 1, 102, B>,由于epoch相同,C的zxid小于B的zxid,则C的选票落选。需要保存B的选票<2, 1, 102, B>,并变更自己的选票为<2, 1, 102, C>
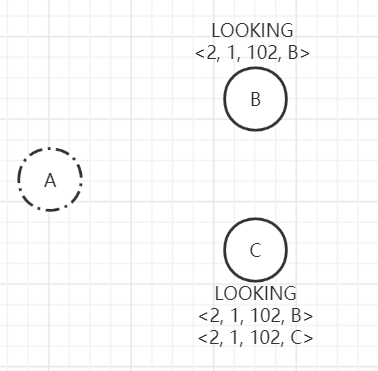
C节点在变更自己的选票信息后,会重新广播选票<2, 1, 102, C>给其他节点。B, C节点都收到来自C的新选票信息<2, 1, 102, C>,根据规则继续PK,结果肯定是B, C都保存两个选票(<2, 1, 102, B>, <2, 1, 102, C>)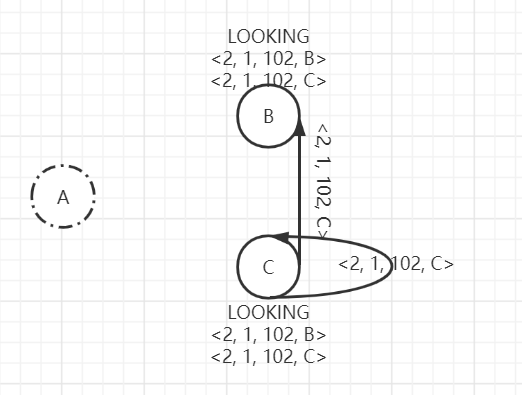
最后,B, C所提议的领导者节点ID为2(即B节点),赢得了过半选票。则B竞选为准Leader,退出LOOKING状态,变更为LEADING,C节点变更状态为FOLLOWING,完成Leader选举。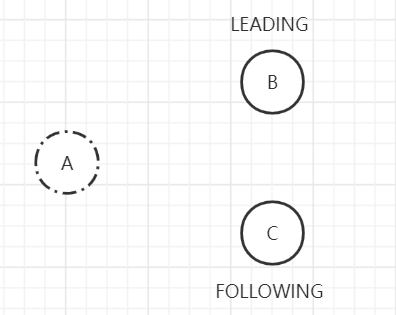
逻辑时钟
这里需要补充的是逻辑时钟,逻辑时钟也会影响Leader的选举,单独拎出来是为了描述选举算法时思路更清晰。
逻辑时钟(logicclock),即选举的轮次,避免接收到旧的选票信息。每进行一轮选举,逻辑时钟变会增加。在选举中,逻辑时钟大的节点不会接收来自逻辑时钟小的节点的选票。
比如,节点A, B的逻辑时钟分别为1, 2,那么B将拒绝接收来自A的选票信息。即使A的zxid大于B的zxid,B也会拒绝接收该选票。
发现(DISCOVERY)
该阶段用于确立Leader的领导关系,继上一阶段,也就是ELECTION完成后,每个节点都有自己所保存的选票池,当选池中有过半的选票都提议同一节点为Leader时,则进入发现(DISCOVERY)状态。
本节思路:会先按每一小步介绍过程,后面会画出整个过程的周期,所以每一小步会记作一个标记,方便后面描述整个过程。
继续上一小节的案例。A, B, C三个节点,A宕机了,B为新选举的准Leader。其中B已提交两个Proposal(<1, 101>,<1, 102>),C只提交了<1, 101>。
在该状态期间,由Follower会主动联系准Leader,并将自己最后接受的事务Proposal的epoch值发送给准Leader,这里记作FOLLOWERINFO。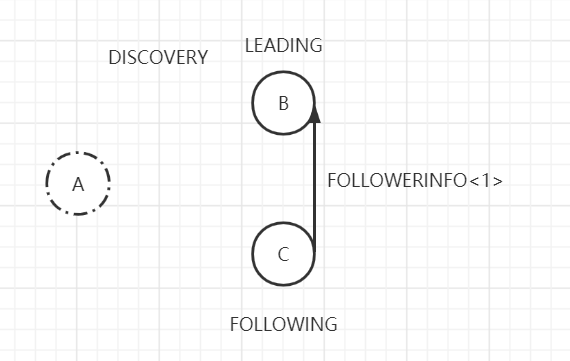
准Leader收到来自过半(包含B节点自己)的FOLLOWERINFO消息后,会从这个FOLLOWERINFO中选取最大的epoch值,对其进行加1,作为新的epoch值,并封装成LEADERINFO消息发给这些过半的Follower。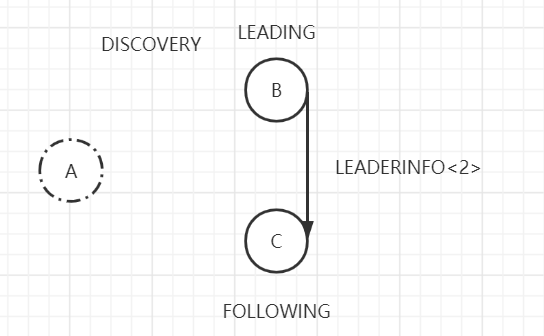
当Follower收到LEADERINFO消息后,会先校验LEADERINFO消息正确性。校验自己的epoch是否小于LEADERINFO消息中的epoch,如果小于,就将LEADERINFO消息中的epoch赋值给自己的epoch,并将自己的运行状态变更为SYNCHRONIZATION,最后向准Leader返回Ack响应(ACKEPOCH)。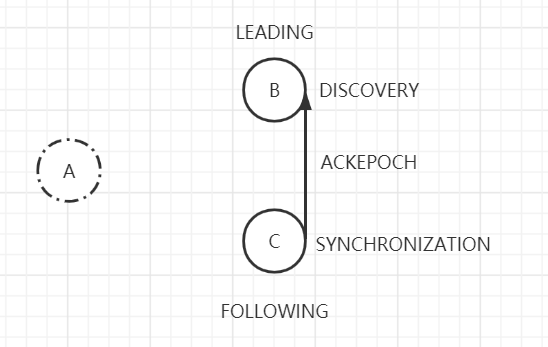
最后准Leader收到过半的ACKEPOCH消息后,也将自己的运行状态修改为SYNCHRONIZATION。至此完成发现阶段的工作,集群确立Leader的领导关系。
数据同步(SYNCHRONIZATION)
进入到数据同步阶段,我们需要先了解三种同步方式(DIFF、TRUNC、SNAP)。Leader会根据每个Follower的最大zxid,采用不同方式处理不一致的数据。
在ZAB的设计中,Leader为了更高效的将Proposal复制给Follower,会在自己的内存队列中缓存一定数量(默认500)的已提交的Proposal。在内存中的Proposal就有zxid的最大值和最小值,即:maxCommittedZxid和minCommittedZxid。
- DIFF:当Follower最大的zxid小于maxCommittedZxid且大于minCommittedZxid
- TRUNC:当Follower最大的zxid大于maxCommittedZxid时,该方式要求Follower丢弃超出的那部分Proposal
- SNAP:当Follower最大的zxid小于minCommittedZxid时,该方式直接同步快照给Follower
了解了同步方式,接下来来看看具体怎么交互的吧。该阶段由Leader根据Follower的最大zxid来选择同步方式和需要发送的数据。由于B已提交两个Proposal(<1, 101>,<1, 102>),C只提交了<1, 101>。该情况下Leader会选择DIFF的方式,并且和需要同步的数据,一起封装为NEWLEADER消息发给Follower。
Follower在收到NEWLEADER消息后,进行修复不一致数据,并返回给Leader响应Ack消息。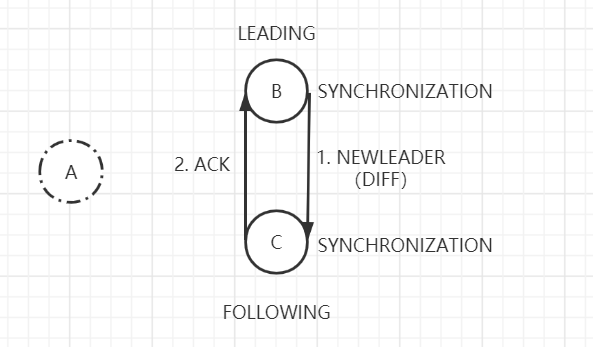
Leader在收到过半Ack消息后,则完成数据同步阶段,将自己运行状态修改为BROADCARST(广播状态),并发送UPTODATE消息给过半的Follower,通知他们完成数据同步,修改运行状态修改为BROADCARST。
整体回顾
与paxos区别
- ZAB采用的是主备模式的系统架构,相比于paxos不同的是,paxos可以同时存在多个提议者进行提案,而ZAB同一时间只允许一个领导者进行提案,这样即解决客户端并发处理,又能规定提案的顺序性。
思考几个题目吧
zookeeper提供的最终一致性,任何节点都能处理读请求,但是读到的可能会是旧数据,如果必须要读到最新数据,怎么办?
1
2zookeeper提供解决方案就是:sync命令。
你可以在读操作之前,先执行sync命令,这样客户端就能读到最新数据了。A, B, C三个节点,A为Leader,B有2个已提交的Proposal(<1, 101>, <1, 102>),C有3个未提交Proposal(<1, 101>, <1, 102>, <1, 103>)。当A故障后,B和C谁会当选Leader呢?
1
2
3
4答案是C。
因为竞选Leader时,使用的是所有已提出的Proposal最大zxid。
C最大的zxid为103,而B最大的zxid为102。
那么C当选Leader。在选举中,会出现选票被瓜分、选举失败的问题吗?
1
2
3不会出现选票被瓜分导致选举失败的情况。
因为每个节点的节点ID都是不同的,而节点ID会参与选票的判断。
在epoch、zxid都一致情况下,还有节点ID可以兜底来保证选票给哪一个节点。有一个Proposal,在广播之前Leader宕机,经过崩溃恢复模式后,该Proposal是否会被提交?
1
2
3不一定,取决新当选的Leader是否包含该Proposal
如果上一任Leader,在广播第一阶段有个Follower收到了。而新当选的Leader又是该Follower
则该Proposal会被提交。在崩溃恢复后,Leader首先将自己的状态设置为广播,然后再通知其他节点修改。那么这是有写请求进来,会执行成功吗?
1
2会,这就是ZAB设计消息发送队列的原因,在Leader为广播状态时即可对外服务。
因为新封装的Proposal请求,一定会在通知其他节点数据同步完成的消息(UPTODATE)之后处理
- 本文链接:https://www.ofcoder.com/2020/08/12/theory/%E5%88%86%E5%B8%83%E5%BC%8F%E4%B8%80%E8%87%B4%E6%80%A7%E5%8D%8F%E8%AE%AE%20-%20ZAB/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享